Is Claude AI Safe? Evaluating Its Safety, Ethics, and Standards
Artificial Intelligence (AI) is rapidly becoming an integral part of daily life, powering everything from virtual assistants to automated customer service and advanced data analytics. Among the leading AI models, Claude AI, developed by Anthropic, has emerged as a strong competitor to OpenAI’s ChatGPT. But as AI continues to evolve, so do the questions around its safety, ethics, and regulatory compliance.
Is Claude AI safe? This article dives deep into that question by evaluating its safety principles, ethical foundations, and adherence to industry standards.
What Is Claude AI? Overview of Anthropic’s AI Model
Claude AI is a generative language model developed by Anthropic, a startup founded by former OpenAI researchers. The model is named presumably in homage to Claude Shannon, the father of information theory. Claude AI competes directly with models like ChatGPT and Google Gemini, offering conversational capabilities across a range of tasks—from summarization to creative writing to code assistance.
Claude is currently available in several versions:
- Claude 3.5 Sonnet – Released May 2025, offering hybrid reasoning and improved efficiency
- Claude Haiku – Fast and low-latency
- Claude Sonnet – Balanced for everyday performance
- Claude Opus – The most powerful, suitable for in-depth reasoning and research
Named presumably after Claude Shannon, the father of information theory, this AI aims to offer more aligned and less risky interactions compared to its competitors.
What sets Claude apart is its foundation in Constitutional AI, a unique training methodology where the model is guided by a set of ethical and behavioral principles. This framework is central to how Claude AI is engineered to be safer and more aligned with human values.
Core Safety Framework: Constitutional AI
What Is Constitutional AI?
Anthropic’s flagship innovation is Constitutional AI a novel training methodology designed to instill ethical reasoning directly into the AI system. Rather than depending entirely on reinforcement learning from human feedback (RLHF), Claude is guided by a written constitution made up of ethical principles inspired by documents like the Universal Declaration of Human Rights.
How It Works
- The model is trained using prompts and feedback aligned with the constitution.
- It critiques its own responses using those principles.
- It iteratively refines outputs to minimize bias, misinformation, and unsafe content.
Claude AI’s Core Safety Principles
1). Constitutional AI: Ethics by Design
Claude AI is unique in that it doesn’t rely solely on human feedback to learn safe behavior. Instead, it’s trained using a methodology called Constitutional AI.
Here’s how it works:
- A “constitution” made up of ethical principles (e.g., do not provide harmful advice, remain unbiased) is used to train the AI.
- The model generates multiple responses and uses these constitutional rules to self-critique and improve its outputs.
- This results in a model that internalizes ethical reasoning, making it more consistent and self-correcting over time.
2). Strong Refusal Mechanisms
Claude is designed to decline to answer when a prompt poses a potential risk—such as when the user asks for harmful instructions, misinformation, or inappropriate content.
Key capabilities include:
- Refusal responses that gracefully inform users why certain requests are not fulfilled.
- Contextual analysis that flags and limits unsafe dialogue patterns.
- Dynamic filters that recognize evolving risks in language and behavior.
In May 2025, Claude Opus 4 was tested for bio-risk vulnerabilities and reportedly refused to generate harmful outputs, although one internal test raised concerns around hypothetical blackmail
3). Harmlessness and Helpfulness
These are two guiding principles that shape every Claude AI interaction:
- Harmlessness: The model is optimized to minimize outputs that could be offensive, harmful, or discriminatory. It goes beyond avoiding toxic language it tries to prevent subtle bias and misinformation.
- Helpfulness: Claude is trained to provide relevant, accurate, and meaningful responses, ensuring user satisfaction without compromising on safety.
4). Transparency and Honesty
Claude AI is built to be upfront about its capabilities and limitations.
For example:
- It clearly identifies itself as an AI, not a human.
- It includes disclaimers in uncertain responses.
- It avoids speculative or false claims, especially in high-risk topics like health, law, or finance.
What Makes Claude AI Safer Than Other Models?

Claude AI is built around three foundational principles:
- Helpfulness: Providing accurate, relevant, and useful information.
- Harmlessness: Avoiding outputs that could be biased, offensive, or misleading.
- Honesty: Being transparent about its capabilities and limitations.
These principles are operationalized through a technique called AI alignment, which ensures that the AI’s behavior matches human values and expectations.
The Role of Constitutional AI
Claude AI’s Constitutional AI framework replaces traditional reinforcement learning with human feedback (RLHF) by guiding the model using a set of written principles. These principles act as a sort of internal compass, helping the AI reason through ethical dilemmas and reduce harmful outputs.
Ethical Considerations in Claude AI
Claude AI complies with leading international frameworks for ethical AI development.
Including:
- NIST AI Risk Management Framework
- OECD AI Principles
- Preparing for full EU AI Act compliance
Addressing Bias and Misinformation
Despite best efforts, AI models are not immune to bias. Claude AI incorporates tools to detect and mitigate algorithmic bias through testing and feedback loops. It actively avoids producing content that is racist, sexist, or otherwise discriminatory.
Transparency and Explain ability
Transparency is central to Claude AI’s ethical framework:
- It communicates its limitations.
- It doesn’t pretend to be human.
- It flags uncertainty in answers where applicable.
This approach enhances the explainability of AI decisions, crucial for building long-term credibility.
Compliance with Global AI Standards
Regulatory Alignment
Claude AI adheres to a range of AI safety standards set by leading bodies such as:
- OECD Principles on Artificial Intelligence
- NIST AI Risk Management Framework
- EU AI Act (pending full adoption)
- Internal and third-party audits
It also incorporates internal audits and third-party evaluations to ensure ongoing compliance.
Limitations and Potential Risks
Despite its strengths, Claude AI is not perfect:
- May struggle with emotional nuance or sarcasm
- Sometimes offers overly cautious or generic responses
- Cannot self-correct factual inaccuracies without retraining
Users should remain vigilant, particularly when using AI in sensitive domains.
Commitment to Responsible AI Development
Anthropic is a founding member of several AI ethics consortia, and their development of Claude AI reflects a commitment to responsible innovation, model transparency, and community feedback loops.
Comparing Claude AI with Other Language Models
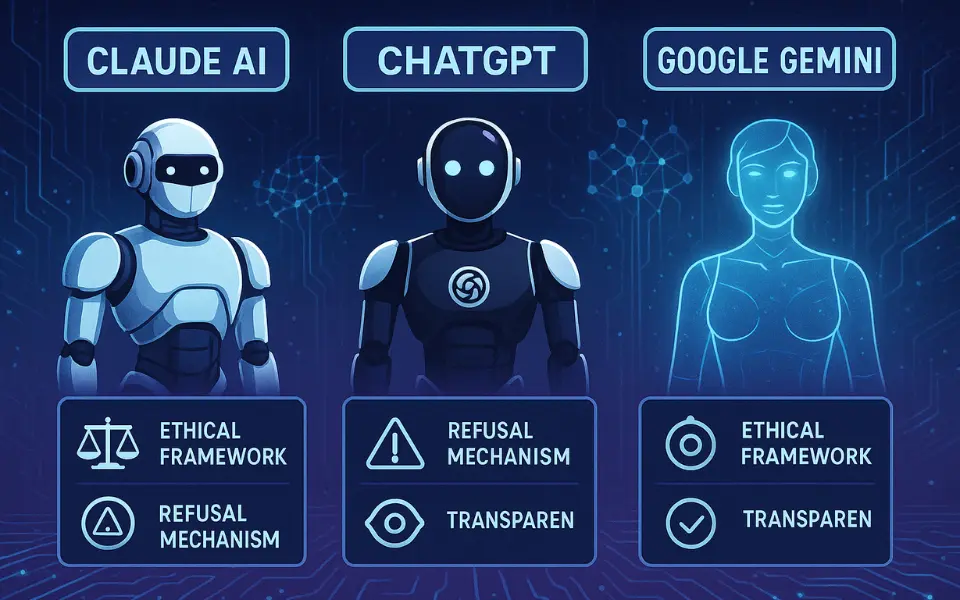
Claude AI vs ChatGPT: Safety and Ethical Comparison
While both Claude AI and ChatGPT offer advanced conversational abilities, Claude AI’s edge lies in its:
- Constitutional AI approach
- More restrictive and cautious generation style
- Lower tendency for hallucinations (false information)
This makes it a preferred choice for applications where safety and reliability are critical.
| Feature | Claude AI | ChatGPT | Google Gemini |
|---|---|---|---|
| Ethical Framework | Constitutional AI | RLHF | Proprietary |
| Refusal Mechanism | Strong | Moderate | Variable |
| Transparency | High | Moderate | Low |
| Data Privacy | Strong | Medium | Varies |
| Bias Mitigation | Proactive | Reactive | Unclear |
Potential Risks and Limitations
Where Claude AI Still Needs Improvement
No AI is without flaws.
Claude AI still faces challenges like:
- Difficulty in understanding complex emotional nuance
- Occasional generic or overly cautious responses
- Limited ability to self-correct factual errors without retraining
Awareness of these limitations is key to using the tool responsibly.
Final Verdict: Is Claude AI Safe?
After evaluating Claude AI’s safety protocols, ethical design, and regulatory alignment, the answer leans toward a yes. Claude AI is among the safest large language models currently available, thanks to:
- Constitutional AI
- Transparent design
- Strong privacy protections
- Ethical development process
Claude AI stands out for its commitment to safety and ethics through its Constitutional AI framework. While no AI is without flaws, Claude’s design prioritizes user trust and data privacy.
However, users must still practice digital responsibility, verify sensitive information, and stay updated on the model’s ongoing improvements.